Creating a Conlang Family Part 10: Romanization
Hello! This time, we interrupt our regularly scheduled programming of morphology for romanization! As a warning, this post is going to be fairly chart-heavy. I’m just going to show the completed IPA tables with their romanizations, and briefly discuss some of the choices I made in making them. Let’s get into it!
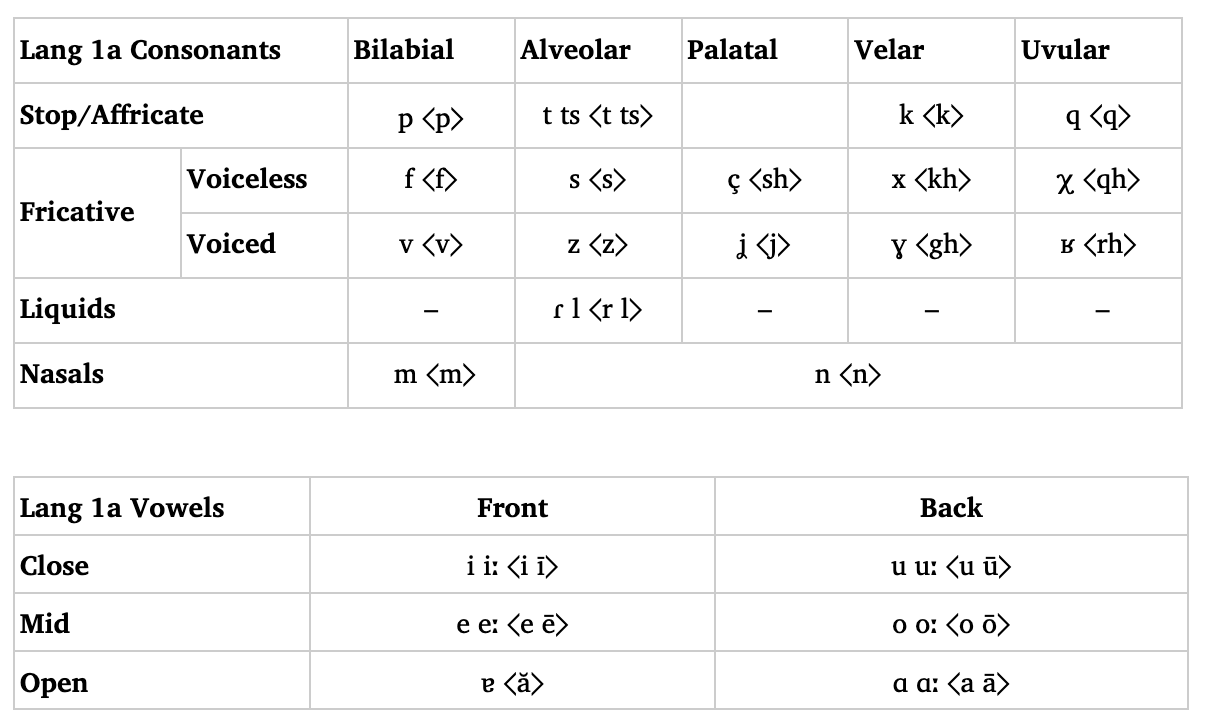
Some things to note:
The use of ⟨ă⟩ for /ɐ/, inspired by the Romanian use of ⟨ă⟩ for /ə/.
The use of ⟨rh⟩ for /ʁ/. As far as I know, this isn’t precedented. However, in the languages that have /ʁ/ as a dedicated phoneme, the prevailing standard seems to be ⟨ğ⟩, which I am not a fan of.
The use of ⟨j⟩ instead of ⟨zh⟩. I just like it better for this language.
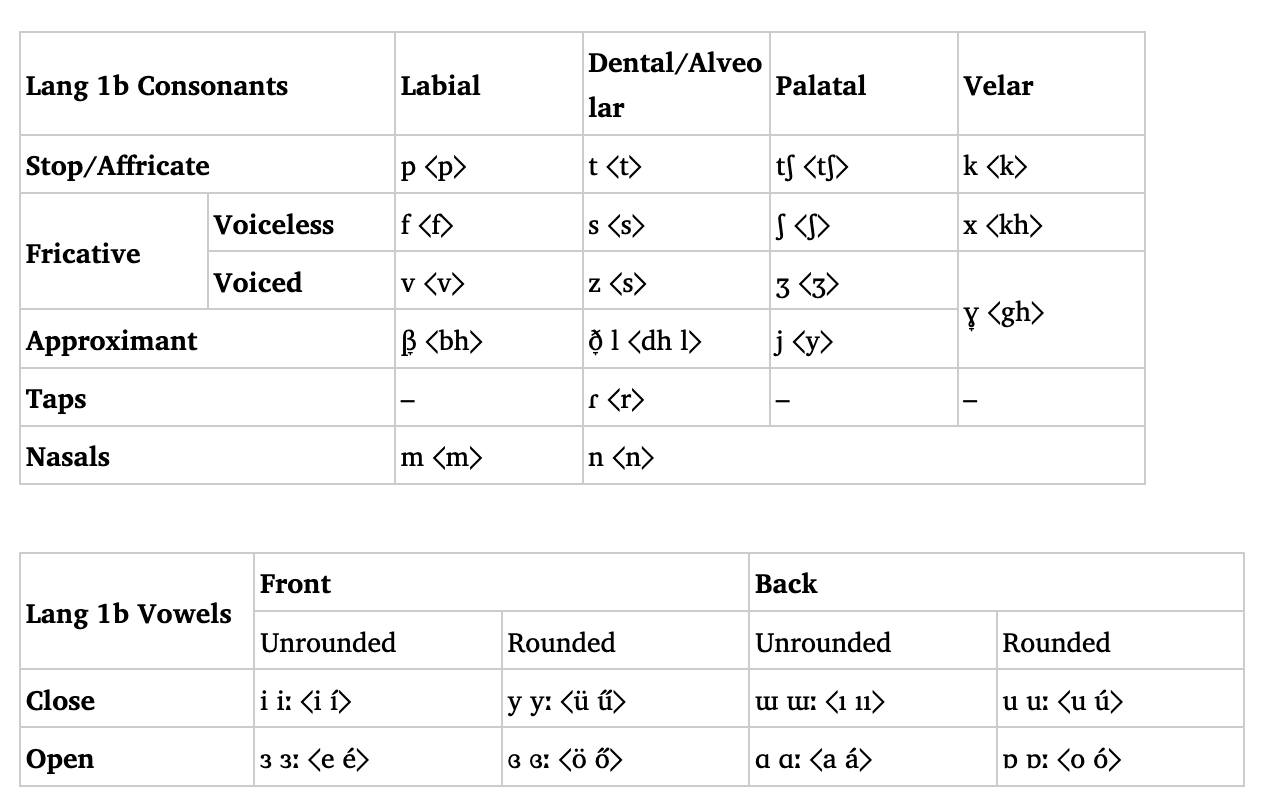
The vowel system’s romanization is very wacky, probably because the vowels themselves are pretty weird. That’s one of the shortcomings of romanization – it has issues when dealing with extremely non-latin-like phonologies. This may not be the final version, but it’s good enough for now. Some things to note:
Acute accents for long vowels, including double acutes for long umlaut vowels – think Hungarian. I like this better than double letters, because ⟨oo⟩ and ⟨ee⟩ are weird for English speakers, and I just don’t like the look of ⟨öö⟩.
A digraph for /ɯː/. I just couldn’t figure out how to distinguish ı with an acute accent from í. Besides, ıı looks cool. However, it’s not great, and I may change it later.
The very English-y ⟨o⟩ for /ɒ/.
The digraphs for the approximants. Yeah, I could have used the single letters /b d g/, but the language is already non-intuitive enough.
So that’s the romanization! With that out of the way, we can get back to our next order of business: more morphology!
…Wait, we’re going to be making protolanguage 0 instead?
…Why are we doing that now?
…OK, I guess we’re doing it. Next order of business: figuring out protolanguage 0!